Page Scanner Addon
Check Webpage Source Code
Page Scanner Addon
- Included Free with ScrapeBox
- Multi-Threaded Connections
- Proxy Support
- Automator Support
- Excel and txt data export
- Statistics of Footprints
- Regex Support
- Selectable Footprint Files
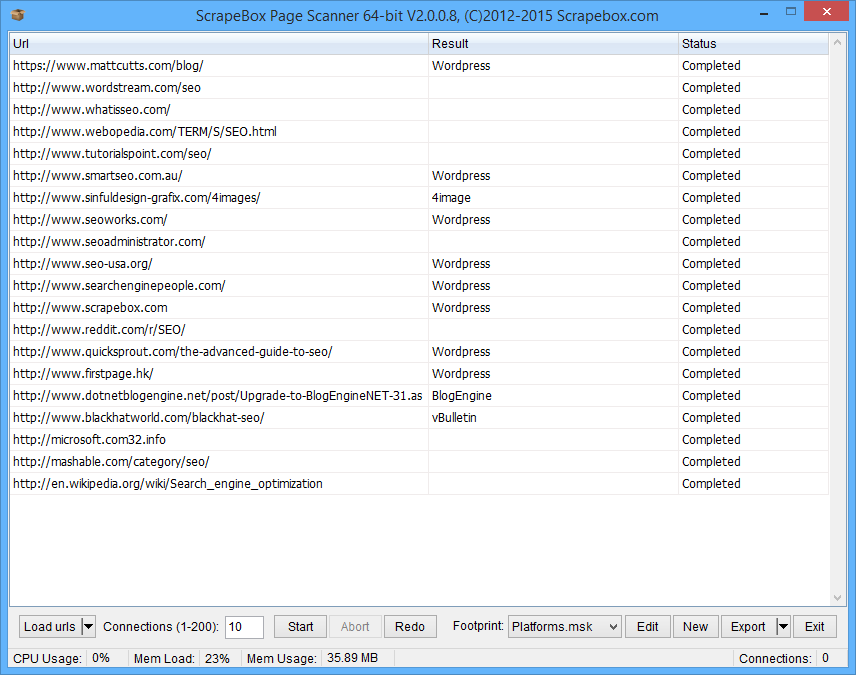
The ScrapeBox Page Scanner is a free addon which allows you to load a list of URL’s, and scan the source code of the pages for specific text or HTML including images, javascript or css. This is ideal for analyzing and identifying CMS platforms, reporting which sites run Adsense or even identifying which sites mention your company name.
You can also use it to filter web pages that contain bad words, find web pages with specific keywords related to your site, find web forms or find the possibilities are endless. Some SEO companies have mentioned they use it to get work by finding blogs using outdated versions of WordPress and offering to update their sites, or finding blogs with no basic on-page SEO elements like Meta Description, rel=”canonical” or All In One SEO Pack installed and offering them SEO.
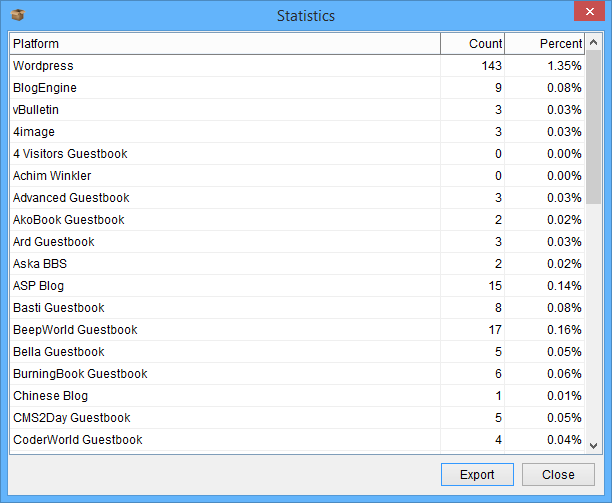
You can view statistics of what footprints were found, and export the statistics to xlsx for viewing in Excel. Or all URL’s can be exported in to individual txt files classified based on their footprint.
{kind=link}
{kind=link}
Custom Footprints
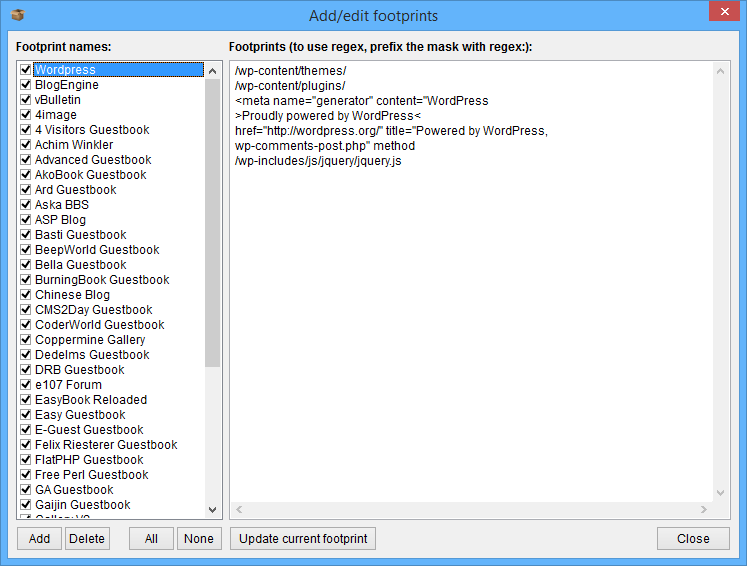 Powerful custom footprint options enable you to create custom scans to search through web pages source code for anything including text, HTML, images, javascript, CSS or a combination of all these things.
Powerful custom footprint options enable you to create custom scans to search through web pages source code for anything including text, HTML, images, javascript, CSS or a combination of all these things.
We have included a definition file for many popular CMS platforms which means the Page Scanner can be used to identify platforms for the most common content management systems and bulletin boards.
You are free to edit, add or change these. And you can create as many databases as you wish for identifying different things.
Advanced Variable Support
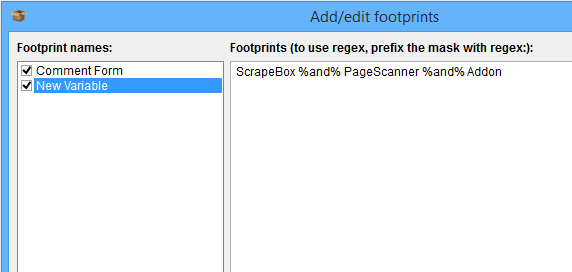 Trainable scanner with the ability to use variables, as well as regex for advanced pattern matching.
Trainable scanner with the ability to use variables, as well as regex for advanced pattern matching.
In the example on the right, by using the %and% token the Page Scanner will only report “Found” if the page contains the words ScrapeBox, PageScanner and Addon anywhere on the page.
It will not report Found if it only contains just one or two of the words.
For power users, you can even use regex for advanced pattern matching.
To use regex simply add regex: to the beginning of your footprint and the whole line will be interpreted as regex.
Page Scanner Tutorial
View our video tutorial showing the Page Scanner in action. This is a free addon included with ScrapeBox, and is also compatible with our Automator Plugin.
We have hundreds of video tutorials for ScrapeBox.
View YouTube Channel